WordPress 4 zu 5 und falsche Zeilenumbrüche sanieren
Thema: Ubuntu – MariaDB – WordPress – Apache – CleanBlogg Theme.
Das Problem
Beim Update von WordPress 4 zu WordPress 5 werden die Posts im alten Format übernommen. Diese editiert man besser weiter mit dem Plugin Classic Editor weil man sonst alle Absätze in Blöcke zerlegen müsste. Trotzdem werden alle Absätze nur mit einem Zeilenumbruch angezeigt (ausser wenn Medien dazwischen geschalten sind). Der Text erscheint als lange Wurst und ohne erkennbaren Absätzen.
Das liegt daran, dass WordPress 5 die alten Einträge als einen einzigen Block interpretiert und darin gibt es nur Umbrüche aber keine Absätze. Konkret ist in der Datenbank ein alter Absatz im Fliesstext so markiert:
... oder die Menge zu bestimmen.\nJa, es stimmt, man kann die ...
Im Frontend und auch im Editor im Backend wird der Text unter WordPress 5 so ausgegeben:
... oder die Menge zu bestimmen.<br />Ja, es stimmt, man kann die ...
Das erzeugt natürlich nur einen einfachen Umbruch. Man kann nun alle Seiten händisch editieren und alle Umbrüche herauslöschen und neue Absätze setzen. Da wir aber in einem <p>Absatz</p> sind, müsste statt dem <br /> eben ein Absatz enden und ein neuer anfangen, was so aussehen sollte:
... oder die Menge zu bestimmen.</p><p>Ja, es stimmt, man kann die ...
Vorwarnung
- Das Ersetzen erfolgt direkt in der Datenbank und ist nur durch entsprechende ähnliche reguläre Ausdrücke eventuell rückgängig zu machen!
- Dieser Vorgang gilt nur für alte Post aus WordPress 4, welche unter WordPress 5 mit dem Classic Editor weiter editiert werden. Öffnet man diese Posts mit dem Gutenberg-Editor, werden diese mit vielen überflüssigen Umbrüchen angezeigt.
Die Abhilfe
Das kann man generell in der Datenbank en bloc ändern. Siehe Eingesetzte WordPress-Plugins.
Beim Ersetzen muss man aber aufpassen, dass man nur echt im Text den Absatzwechsel einführt, also nicht zwischen Text und Medien (beginnen mit [) bzw. Listen und anderen HTML-Code (beginnen mit <).
Man kann nun bei der Suche diese beiden Zeichen ausschliessen, das ginge so:
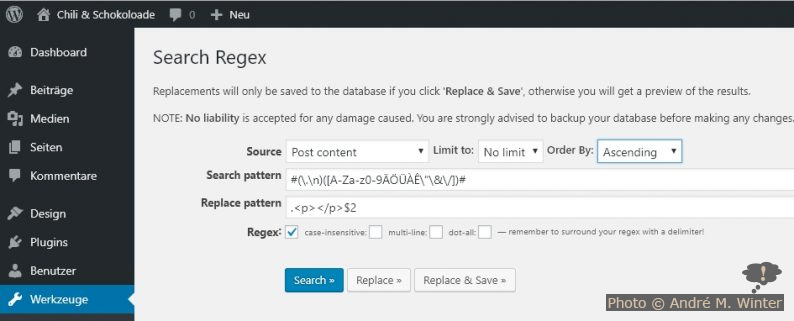
#(\.\n)([^\[\<])#
Die Treffer in runden Klammern sind werden gespeichert und können beim Ersetzen mit $1, $2 etc. eingesetzt werden. Streng genommen ist die erste runde Klammer nicht nötig, aber sie verschafft Überblick. Dort befindet sich nämlich der gesuchte Begriff (den Punkt muss man mit \ maskieren). Der zweite Block an runden Klammern dient nur der Erkennung ob wir den Umbruch im richtigen Kontext ersetzen. Da dieser Teil (konkret nur das erste Zeichen) auch in der Suche gefunden wird, müssen müssen wir diesen Treffer auch beim Ersetzen wieder hinzufügen (unten mit $2). Das ^ bedeutet, dass man die darauf folgenden Klammern nicht finden will (beide sind zudem maskiert). Die # gehören als Anfang und Ende zum regulären Ausdruck.
Oder man sucht gezielt nach darauf folgenden Zeichen. Die Buchstaben sind selbsterklärend, dahinter sind Anführungzeichen, das &-Zeichen und ein Schrägstrich, mit welchen bei mir auch einige Zeilen begonnen haben. Darunter eine Variante, die bei einem origineller layoutiertem Blog notwendig war:
#(\.\n)([A-Za-z0-9ÄÖÜÀÊ\"\&\/])#
#(\.\n)([A-Za-z0-9ÄÖÜÀÊ\"\&\/\[\<\★\-])#
Will man vor dem Ersetzen noch andere Zeichen finden, die vielleicht auch ersetz werden würden, kann man die Suche so kombinieren, dass man alles bekannte ausschliesst, eben so:
#(\.\n)([^A-Za-z0-9ÄÖÜÀÊ\"\&\/\[\<])#
Hier sollte keine Treffer mehr erfolgen. Wenn doch, kann man besagte Zeichen oben bei der Negativ-Suche oder der gezielten Suche hinzufügen.
Ersetzt wird durch:
.<p></p>$2
Die Änderung erfolgt unmittelbar und ist im Frontend sofort sichtbar.
Editiert man später ein Post mit dem Classic Editor , so werden beim Speichern die Umbrüche wieder sauber hergestellt.